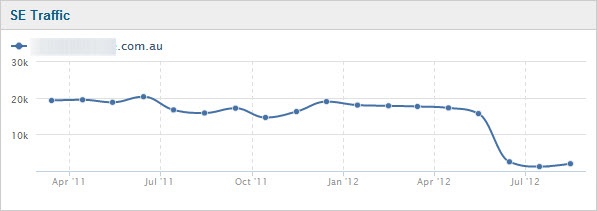
This is what losing money looks like. The following graph shows the daily traffic for a quality consumer information site (I was brought in to analyse the issue this week):
The pain starts in early May and then turns to heartbreak as traffic declines over the following month. From almost 20K visits to under 2K visits daily. That's a 90% drop in traffic. And for this site - where the business model revolves around referring visitors to suppliers and taking a commission - that's a massive drop in income.
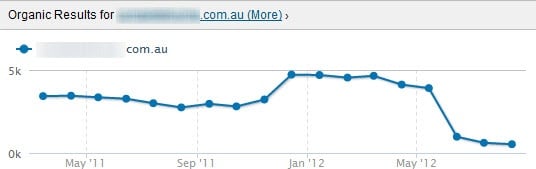
Here's the similar trend in terms of their rankings (ie number of terms they rank for) drop:
So, what happened in early May? Well, that's when they went live with a brand new site. New design, new CMS, new site layout and a new hope...
What caused the drop then? I'll spare you the investigative process (was it the CMS, a site architecture issue, a Google algorithm change, a site content change, a penalty?) and simply cut to the chase - the main problem is they didn't put in redirects from the old site pages to the new pages.
For a site like this one (with close to 5000 pages) it's absolutely crucial that key technical SEO considerations such as redirects are implemented - they simply aren't optional. I say key technical SEO consideration because SEO is a mix of technical configuration and art. Even if you are dubious about the 'art' side of SEO, don't neglect the technical side - things like redirects, robots.txt files, sitemap.xml files, Title tags, proper caching and expiry settings - things that most web developers should understand.
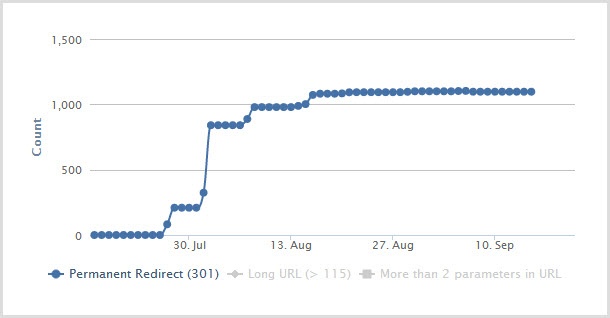
Sadly though, it wasn't until late July that someone realised the redirects were missing and started putting them in place (and only a subset at that):
But by then it was too late - the damage was done and any chance of getting the traffic back quickly is small.
Here's why.
In an ideal world here's how Googlebot would work:
Hmmm, I'm seeing a lot of 404s on the site, but I know the site is OK because the home page is fine, and the first level of links are all crawlable. Plus I've had a good history of crawling this site. I wonder if they've moved to a new system and are using a new URL structure. I'll check. Yes, it looks as though they are. I'll use some of my infinite crawling and indexing resource to go through the entire new site and intelligently update the old links I have in my index with the new ones.
Sadly though, that's not how it works. Here's a more accurate picture of how Googlebot works:
WTF? I'm getting lots of 404s on this site. I'll check back tomorrow and see if the errors are still occurring. Yep, looks like there are still lots of errors. Well I'm not going to waste much of my finite crawling and indexing resource on this site. In fact I'm going to significantly reduce how much resource I allocate the site, and also drop the thousands of pages that are giving me 404s from my index. Ahh that's better, I only have a few hundred pages to worry about now. And in the coming months I might (just might) spend a tiny bit of resource looking for new pages on the site.
Admittedly the above is greatly simplified - Googlebot is actually incredibly sophisticated (it does all sorts of cool things like indexing the content in lazy loading javascript comment plugins) - but on the crawling basics the above is what you can expect.
With a new site the redirects need to be in place from day one - they can't just be added later. Redirects aren't like a performance tune-up ('ooops I forgot to add caching on the server - I'll just add that now') - once your URLs are out of Google's index, they're gone.
Implementing 301 redirects is actually really easy (although preparing the actual mappings of old to new pages can be very time-consuming).
For bulk redirects (a new site going live), these are normally done at the server level.
On Windows/IIS hosting the easiest way is to configure IIS redirects is via rewritemaps.config files. These are simple text files placed in the same directory as the web.config file and an entry added to the web.config file that refers to it. Ruslan covers using rewritemaps.config files really well.
My usual process when engaging with larger companies who use IIS is to provide their IT team with a fully prepared rewritemaps.config file which they just need to place on the server. I never have to go near their servers or even be given FTP access to anything.
On Linux/Apache hosting (the majority of PHP and open source CMS hosting scenarios) redirects are implemented in a .htaccess file (also a simple text file). I won't go through the details - there's hundreds of posts on how to set up .htaccess files, but here's a typical example of a redirect line in a .htaccess file (from this site), it's super simple:
Redirect 301 /live/post/2004/06/27/Single-Malt-Scotch.aspx http://www.craigbailey.net/single-malt-scotch/
My site currently uses WordPress, before that it was BlogEngine, before that it was a custom rolled blog [hey, we've all been there :-)], and before that it was Blogger, so there's been some changes over the years. Because of that my current .htaccess file has more that 1100 redirects from old URLs to current locations. These all sit in the .htaccess file at the domain root.
Both IIS and Apache redirects support cross domain redirects, and both support parameters as well.
Increasingly you can set up redirects within the CMS used as well.
For example, in WordPress I always install the Redirection plugin. This can help with bulk URL changes eg if you change the permalink structure - it will automatically catch the change and set up Redirects for all the old URLs to the new ones. (Make sure you have the plugin enabled before you make the permalink changes!) This plugin will also catch any ad hoc changes made (eg you create a new page, and then a few days later change it's URL).
elcomCMS (a CMS I deal with a lot in enterprises) also has this as a standard feature. Any changes to pages have redirects automatically created for them, and you can easily add multiple redirects for any page. You'd be surprised at how rare this is in the enterprise CMSs.
Preparing the mappings is actually the time consuming part. Most clients I work with these days have production and staging sites. In the weeks leading up to the cutover I request that the staging site be available externally (usually IP limited) so I can fully crawl it. I usually use ScreamingFrog to crawl the staging site and the current (production) site. There's tons of other tools of course eg I also use this one from time to time.
Most CMS have an export tool as well, but I don't typically use them unless I'm familiar with the export format. I'm really familiar with ScreamingFrog so it's my usual go-to tool. I also prefer to use a tool that crawls the site (as opposed to exporting from an internal database) because the URLs discovered will more closely match what Google has likely found in the past (or will find in the future).
From there it's a manual process of matching the old to the new URLs.
I do this in Excel, and depending on patterns in the before and after URLs you can often use sorting, formulas and lookups to help expedite the process. On big sites I usually need to engage with the subject matter experts and content authors to check on information architecture flows. I mention this because it's important to understand any content strategy changes that may be being implemented as part of the new site.
Once my spreadsheet is ready I then simply format the mappings into either .htaccess or rewritemaps.config files and hand over to the client.
This will cover 95% of all the URL changes.
Sometimes there are old links out there that give errors eg an external site might link to a page that no longer exists on your current site. I use backlink tools (eg ahrefs, Majestic, OpenSiteExplorer) to find all the backlinks from other external sites. I run these through a link checker and note any 404s. I then add redirects for these too. This can result in a little boost for the site when it goes live. Bonus!
As mentioned, the time consuming part of setting up redirects is preparing the mappings between old URLs and new ones.
As an example, I was involved in a large-ish Federal Government site revamp last year - they had close to 2000 pages of content, plus hundreds of additional documents (remember Google indexes PDF files and other documents - you can often rank well for PDFs). In that case constructing the redirect mappings alone took me close to 4 whole days. And would have taken much longer if not for the help of the content authors who helped with specific sections of the site. At my hourly rates, that might seem a high price to pay for something that doesn't actually add any additional value, but compared to the potential cost of not doing it, it's a no-brainer.
This is worth highlighting - because the next time you're preparing a large site go-live and the project manager gets a quote for $5K+ just to prepare the redirects, don't be surprised. In the case of the site example at the start, they would have paid for this in a few hours of a typical day (pre traffic fall). Currently they are spending multiples of that working with an agency to incrementally build the traffic up again.
Sadly, not putting redirects in place is something I see far too often. It's probably the biggest issue (in terms of impact) I encounter. And it's totally avoidable. Please ensure you plan for and implement redirects in all your upcoming web projects.
Note: This post is cross-posted from Craig Bailey's blog
{kind=link}
{kind=link}
{kind=link}
{kind=link}